The Patient Is Not a Label: Toward World Models of Physiology
Most clinical AI has learned the shape of the chart. It has not yet learned the patient.
That distinction sounds philosophical until it enters a ward round. A model can predict that a patient is at high risk of acute kidney injury without representing whether the kidney is already injured, whether creatinine is merely lagging behind tubular damage, whether the problem is congestion, hypoperfusion, obstruction, sepsis, nephrotoxicity, or some mixture of all five. A model can predict sepsis without representing vascular tone, oxygen debt, immune dysregulation, source control, fluid responsiveness, antibiotic timing, or the fact that the next lactate will partly depend on what the clinician does now. A model can assign mortality risk without knowing which part of the trajectory is disease, which part is treatment, and which part is a measurement policy masquerading as physiology.
This is the ceiling of label prediction in medicine. It is useful. It is often publishable. It sometimes improves workflows. But it is not the same as understanding the patient as a dynamical system.
The next frontier of clinical AI is therefore not simply a bigger classifier, a larger clinical language model, or a more elaborate dashboard. The interesting object is a physiologic world model: a model that estimates the latent state of a patient over time, updates that state as observations arrive, represents uncertainty, and forecasts how the patient may evolve under different interventions.
The phrase is easy to abuse. “World model” is now used for game engines, robotics simulators, video generators, spatial AI systems, protein models, agent memory, and digital twins. In medicine, that ambiguity is dangerous. If every temporal model becomes a world model, the phrase stops meaning anything. If every patient embedding becomes a digital twin, the field inherits a grand term without the discipline required to make it clinically useful.
So the useful question is not whether world models are fashionable. The useful question is: what would a model need to represent before we should trust it as a model of patient physiology rather than a statistical shadow of the chart?
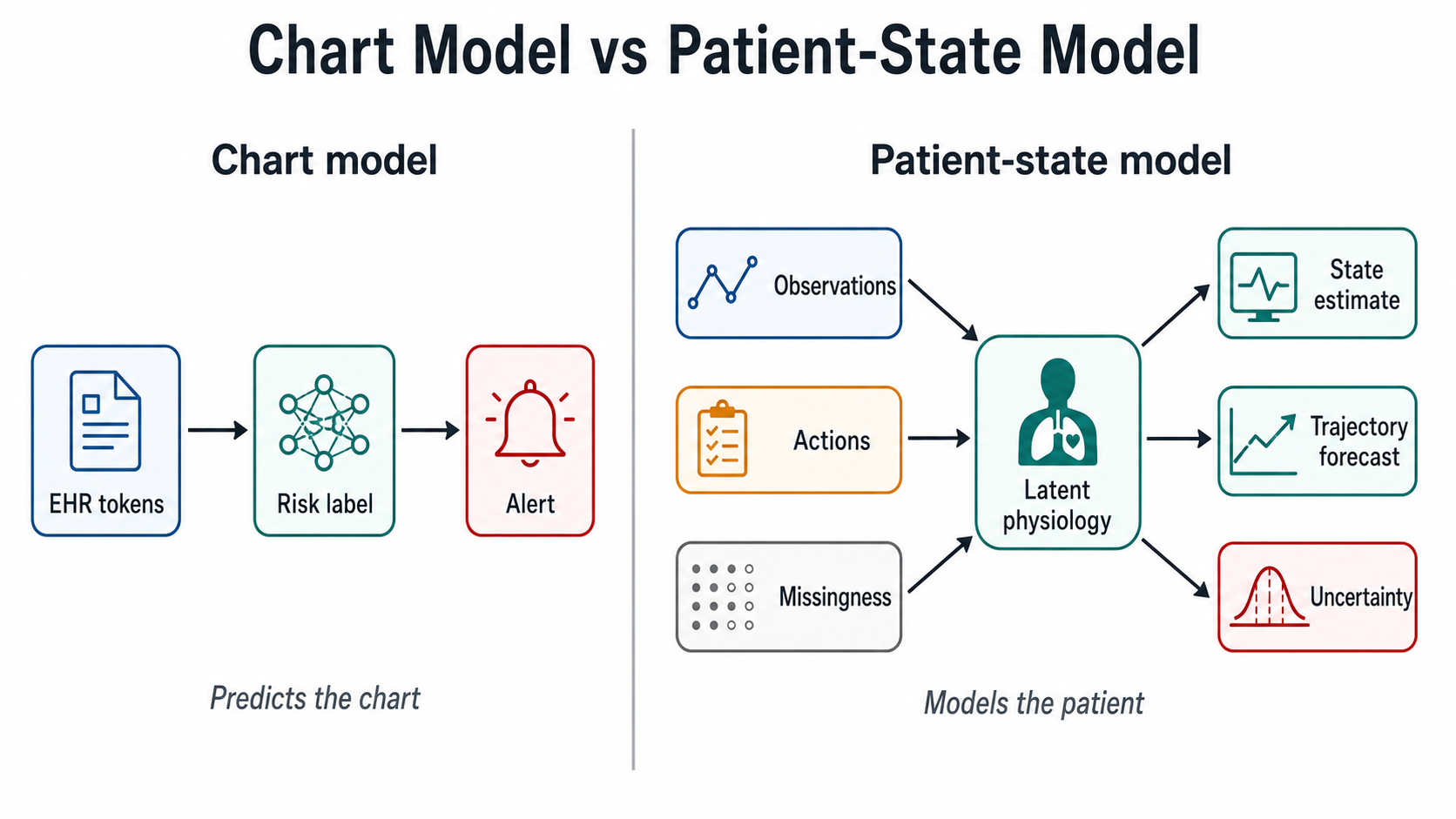
Figure 1. Ordinary chart-level prediction compresses clinical data into labels and alerts. A physiologic world model instead uses observations, actions, missingness, and uncertainty to maintain a patient-state representation.
1. The chart is not the patient
The electronic health record is not a neutral sensor. It is a compressed, delayed, incomplete, clinician-mediated trace of care.
Some data exist because a clinician was worried. Some data are absent because nobody thought to measure them. Some labels are created after the fact by documentation and billing. Some outcomes are prevented by treatment, which means the patient who never deteriorated may be the patient who would have deteriorated without the intervention. Some “features” are actually fragments of the clinical response: vasopressors, antibiotics, CT scans, dialysis starts, ICU transfer, discharge decisions.
This makes ordinary prediction harder than it looks. A model trained to predict sepsis, AKI, readmission, or mortality is often learning a mixture of biology, workflow, documentation style, measurement intensity, and institutional habit. That mixture can still be predictive. It can also be brittle. It may work in the hospital that produced the data and fail elsewhere. It may perform well retrospectively but become less useful when clinicians change their behaviour in response to the alert. It may rank patients correctly but produce too many false alarms to be operationally tolerable. It may achieve a strong AUROC and still be clinically unhelpful.
The core error is treating the label as the thing. “Sepsis in the next six hours” is a label. Shock physiology is a state. “KDIGO stage 2 AKI” is a label. Kidney injury, filtration reserve, renal perfusion, venous congestion, nephrotoxin exposure, and recovery velocity are states or state components. “Mortality risk” is a summary outcome. Organ reserve, disease burden, frailty, inflammatory trajectory, treatment response, and uncertainty are closer to the substrate clinicians reason over.
A model of labels can be useful. A model of state can be useful in a deeper way. It can answer not only “what is the risk?” but “what is changing, why might it be changing, what could happen next, and which action would make that forecast invalid?”
That is the reason world-model language matters in medicine.
2. What a world model actually means
In reinforcement learning and control, the world is not directly observed. An agent takes actions. Those actions change the state of the environment. The agent receives observations, not the true state itself. It learns, explicitly or implicitly, how the world evolves and how its actions alter future observations.
Medicine has the same loop, but with higher stakes and uglier data.
The clinician is an agent. The patient is the environment, although that word is too cold for clinical reality. The hidden state is physiology: intravascular volume, vascular tone, inflammation, oxygen delivery, renal reserve, tumour burden, clot burden, endocrine control, cardiac function, neurologic injury. The observations are partial projections: vitals, labs, notes, ECGs, imaging, waveforms, medications, procedures, symptoms, clinician impressions. The actions are fluids, vasopressors, antibiotics, diuretics, ventilation settings, dialysis, surgery, chemotherapy, anticoagulation, discharge, monitoring intensity, and even communication.
A physiologic world model should therefore contain at least four pieces.
First, it needs a latent patient state: a time-indexed representation of the patient that is not merely a bag of observed codes. Second, it needs observation models: ways to interpret each modality as a noisy, delayed, selective view of that state. Third, it needs action-conditioned dynamics: a model of how state changes after interventions, not just how it usually changes in historical records. Fourth, it needs uncertainty: the ability to say when the state is poorly identified, when the patient is outside training support, when modalities disagree, or when a counterfactual claim is too weak to act on.
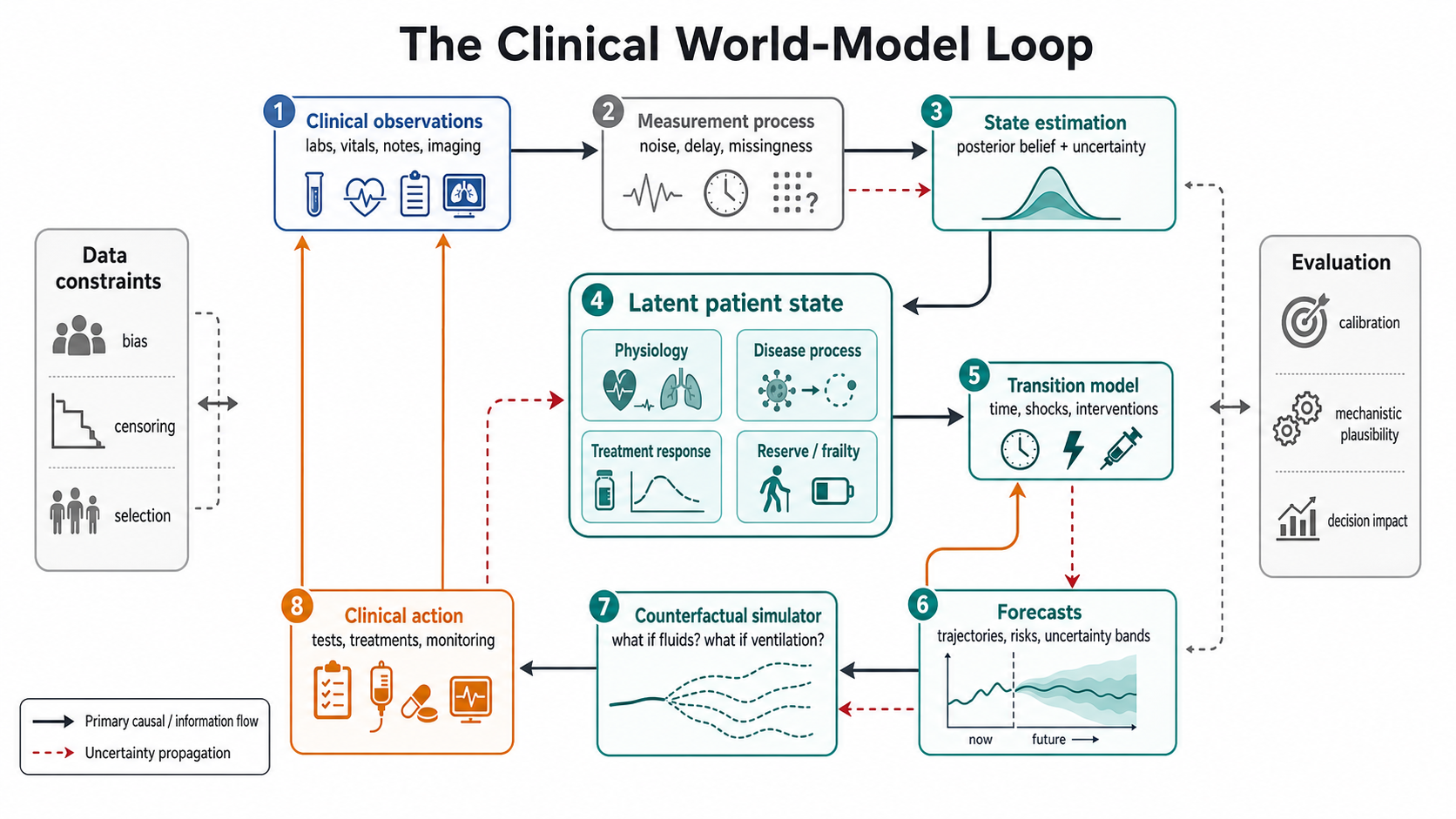
Figure 2. The clinical world-model loop: hidden patient state generates partial observations, clinicians act under uncertainty, and both physiology and measurement policy shape the next state estimate.
In simple notation, the object is something like this:
latent state: z_t
observations: x_t from labs, vitals, notes, ECG, imaging, waveforms, genomics, wearables
actions: a_t from medications, procedures, devices, monitoring and discharge decisions
observation policy: o_t, meaning what was measured and why
transition: p(z_{t+1} | z_t, a_t, context)
emission: p(x_t | z_t)
posterior estimate: p(z_t | history)
The notation is less important than the discipline. The chart is not the state. Treatments are not ordinary covariates. Missingness is not empty space. The future is not independent of the clinician.
3. Why the broader AI field is suddenly talking about worlds
The world-model idea did not begin in medicine. It has roots in control, partially observable Markov decision processes, reinforcement learning, cognitive science, and self-supervised representation learning. David Ha and Jürgen Schmidhuber’s 2018 “World Models” paper made the term memorable for modern neural networks by training an agent inside a learned generative model of its environment. Yann LeCun’s JEPA line of work pushed a different emphasis: instead of predicting every pixel, learn abstract representations that capture the predictable structure needed for reasoning and planning.
The current wave is more visible because world models have moved from papers into frontier labs and products.
World Labs frames the problem as spatial intelligence: AI systems that can perceive, generate, reason about, and interact with the 3D world. Its Marble model is not just an image generator. It is positioned as a multimodal system that can turn text, images, video, panoramas, or layouts into persistent 3D worlds that can be edited, expanded, and inhabited. Google DeepMind’s Genie line takes another route: generate interactive environments that agents or humans can explore in real time, with the model predicting how the environment changes as actions are taken. AMI Labs, associated with Yann LeCun and colleagues, emphasizes action-conditioned world models that operate in abstract representation space and allow agents to plan consequences under safety constraints.
These projects are not clinical tools. A 3D world generator does not solve septic shock. A video JEPA does not solve AKI. A game-like interactive environment does not make an ICU simulator clinically valid. But they clarify the shape of the problem: intelligence requires more than text completion. It requires models that maintain state, support interaction, and represent consequences.
That is precisely the missing layer in much of clinical AI.
4. Biology is already becoming world-model shaped
The strongest evidence that this framing matters for medicine may not come from hospital EHRs first. It may come from molecular biology.
AlphaFold changed the field by showing that learned representations could recover protein structure at a scale and accuracy that traditional pipelines could not match. AlphaFold 3 broadened that ambition from proteins alone toward biomolecular interactions involving proteins, DNA, RNA, ligands, ions, and chemical modifications. The important conceptual move is not only structural prediction. It is the attempt to model biological interaction space: molecules do not matter in isolation; they matter in complexes, binding events, conformational changes, and downstream function.
The Biohub release of a “world model of protein biology” makes this point more explicit. Biohub describes ESMC as a protein language model trained on roughly 2.8 billion sequences, ESMFold2 as a structure and binder-design engine, and ESM Atlas as a navigable map across billions of sequences and predicted structures. The model family is trained on the evolutionary record of life, with the simple objective of predicting amino acids selected by evolution. The claim is that the resulting representations capture a compositional grammar of protein structure and function strongly enough to design new binders that work in laboratory assays.
That is a serious boundary crossing. The model is no longer only classifying known proteins or retrieving similar sequences. It is being used to move from sequence space to structure, from structure to interaction, and from interaction to experimentally testable design.
Medicine should pay attention because the analogy is not superficial. Protein biology and bedside physiology are different regimes, but both involve latent structure behind partial observations. In proteins, the sequence is visible and the functional landscape is learned from evolutionary constraint. In patients, the observations are sparse, noisy, intervention-confounded, and multi-scale. A patient is harder than a protein model in some ways because the “training objective” is not cleanly written into nature. But the direction is similar: move from surface tokens to generative constraints, from recognition to simulation, from labels to mechanisms.
If protein models can learn enough of a biological grammar to design functional binders, clinical AI should become more ambitious than predicting ICD-coded endpoints.
5. Why patients are harder than proteins, rooms, or games
A patient is not a static object, a closed game, or a clean molecular sequence.
The state is partially observed. The measurement process is part of care. Actions are chosen because clinicians already suspect something. The timing of observations is irregular. Disease evolves across multiple scales: seconds for waveforms, minutes for hemodynamics, hours for inflammatory response, days for renal recovery, weeks for oncology toxicity, months for chronic disease progression, years for cardiovascular risk. Causal effects are entangled with treatment policies. Outcomes are censored by discharge, death, transfer, and loss to follow-up. Many clinically meaningful variables are never directly measured.
This means the naive path will fail. It is not enough to pour the EHR into a transformer and call the embedding a world model. A generic sequence model can learn that rising creatinine often precedes nephrology consultation. It can learn that blood cultures often precede broad-spectrum antibiotics. It can learn that ICU transfer is a powerful token. But those correlations do not automatically identify physiology or treatment effect.
The patient-world problem requires clinical factorization. For example:
- In shock, separate vascular tone, preload responsiveness, cardiac output, oxygen debt, inflammatory burden, and organ support.
- In AKI, separate injury, filtration lag, volume status, congestion, nephrotoxin exposure, obstruction, and recovery capacity.
- In heart failure, separate structural disease, rhythm, contractility, congestion, renal interaction, medication response, and adherence.
- In oncology, separate tumour burden, clonal dynamics, immune environment, treatment exposure, toxicity, and radiologic measurement.
A useful world model does not need to be perfectly interpretable in every dimension. But it should be constrained enough that its latent state is not arbitrary. If the model’s hidden space improves prediction but cannot support clinically coherent state estimation, intervention reasoning, uncertainty, or validation under shift, then it may be a good representation model. It is not yet a physiologic world model.
6. The clinical ingredients already exist, but they are fragmented
The report this article is based on makes an important point: no general-purpose, clinically deployed physiologic world model exists yet. What exists is a set of converging traditions.
Longitudinal EHR models learned patient trajectories from visits, diagnoses, medications, labs, and notes. Models such as Deep Patient, Doctor AI, RETAIN, BEHRT, Med-BERT, CLMBR, and newer structured-EHR foundation models showed that patient histories contain reusable predictive structure. They moved the field away from static feature tables and toward temporal representation learning.
ICU models pushed harder on dense physiology. Critical care is the natural laboratory for patient-state modeling because measurements are frequent, interventions are explicit, and consequences arrive quickly. High-resolution early warning systems, irregular-time Gaussian-process models, temporal convolutional models, and sequence models for sepsis, circulatory failure, respiratory failure, and AKI have all built pieces of the stack.
Multimodal models added another necessary layer. No modality sees the whole patient. ECG can expose electrical and sometimes structural disease. Echocardiography sees mechanics. Chest imaging sees spatial disease burden. Notes contain hypotheses, context, negation, and uncertainty. Labs and vitals give biochemical and physiologic traces. Wearables extend monitoring outside the hospital. The correct abstraction is not “concatenate every modality.” The correct abstraction is that each modality is an emission from a hidden patient state, arriving at different frequencies with different noise, bias, cost, and clinical indication.
Digital twins contributed a mechanistic ambition. In diabetes, cardiovascular modeling, oncology, and organ-specific simulation, digital twins make the intervention problem explicit: the model should update to an individual and support what-if reasoning. But many digital twins remain organ-specific, difficult to personalize, weakly validated, or more aspirational than operational.
Causal inference and dynamic treatment regimes contributed the guardrails. Marginal structural models, target-trial emulation, structural nested models, and dynamic regimes exist because treatments are time-varying, confounded, and affected by prior patient state. Offline reinforcement learning contributed useful formulations but also cautionary failures, especially in sepsis. A policy learned from observational ICU data is only as credible as the state representation, action support, causal assumptions, and off-policy evaluation behind it.
The frontier is not the invention of one magical architecture. It is the synthesis of these traditions into clinically scoped systems.
7. What should count as a physiologic world model?
The term should be reserved for systems that satisfy a higher bar than ordinary prediction.
A physiologic world model should estimate patient state over time. It should accept new data as evidence, not merely as tokens. It should understand that a missing lactate, a delayed creatinine, a repeated troponin, and an urgent CT order each carry different information. It should encode interventions separately from observations. It should distinguish a patient who improved spontaneously from a patient who improved after antibiotics, fluids, vasopressors, dialysis, surgery, or oxygen escalation.
It should also forecast trajectories rather than isolated endpoints. A clinician does not only ask whether the patient will deteriorate. The clinician asks how fast, through which organ system, with what degree of reversibility, under which treatment assumptions, and with how much uncertainty. A world model should make those assumptions visible.
Table 1. What counts as a physiologic world model?
| Dimension | Ordinary predictor | Physiologic world model |
|---|---|---|
| Target | A label, endpoint, score, or risk category. | A time-updated estimate of patient state and trajectory. |
| Observations | Treats labs, notes, images, and codes mainly as input features. | Treats each modality as a noisy, delayed, selective view of hidden physiology. |
| Missingness | Imputes, masks, or ignores missing values. | Models what was measured, what was not measured, and why that absence may matter. |
| Actions | Treats treatments as ordinary covariates or historical tokens. | Represents interventions separately and conditions future state on them. |
| Dynamics | Predicts whether an event will occur by a fixed horizon. | Forecasts how organ systems may evolve over time. |
| Counterfactuals | Usually does not support action-specific reasoning. | Separates prediction, simulation, and recommendation, with explicit assumptions. |
| Uncertainty | Reports confidence around a score or endpoint. | Reports uncertainty about state, trajectory, action support, and distribution shift. |
| Validation | Optimizes discrimination, calibration, or benchmark performance. | Requires statistical, operational, physiologic, uncertainty, and prospective validation. |
The minimal clinical outputs should look more like this:
Current estimated state:
- shock phenotype and confidence
- renal injury/recovery state
- respiratory trajectory
- inflammatory burden
- treatment-response uncertainty
Forecasts:
- expected trajectory under current management
- plausible trajectory under candidate actions
- confidence intervals or uncertainty sets
- warning when counterfactual support is weak
Operational translation:
- lead time
- alert burden
- net benefit
- subgroup performance
- calibration drift
- recommended human review pathway
This is different from an autonomous doctor. The goal is not to replace clinical judgment with a black-box simulator. The goal is to make the patient’s evolving state more legible, to expose uncertainty, and to support decisions where timing and trajectory matter.
8. The dangerous temptation: counterfactuals without identification
The moment a model forecasts under alternative actions, it enters causal territory.
This is where many clinical AI claims become fragile. Historical data do not contain randomized treatment choices. Fluids are given because clinicians infer hypovolemia or shock. Vasopressors are started because blood pressure, perfusion, or clinical concern crosses a threshold. Dialysis is initiated after a mixture of laboratory, volume, acid-base, hemodynamic, and institutional considerations. Imaging is ordered because a clinician has a hypothesis. Discharge happens because someone judged the patient safe enough to leave.
If the model ignores this, it may learn the wrong lesson. It may conclude that vasopressors cause mortality because sicker patients receive vasopressors. It may conclude that frequent lactate testing causes sepsis because lactate is measured when clinicians suspect sepsis. It may conclude that ICU transfer predicts deterioration without separating whether transfer is a marker of severity, a rescue intervention, or both.
A credible physiologic world model must therefore separate three claims:
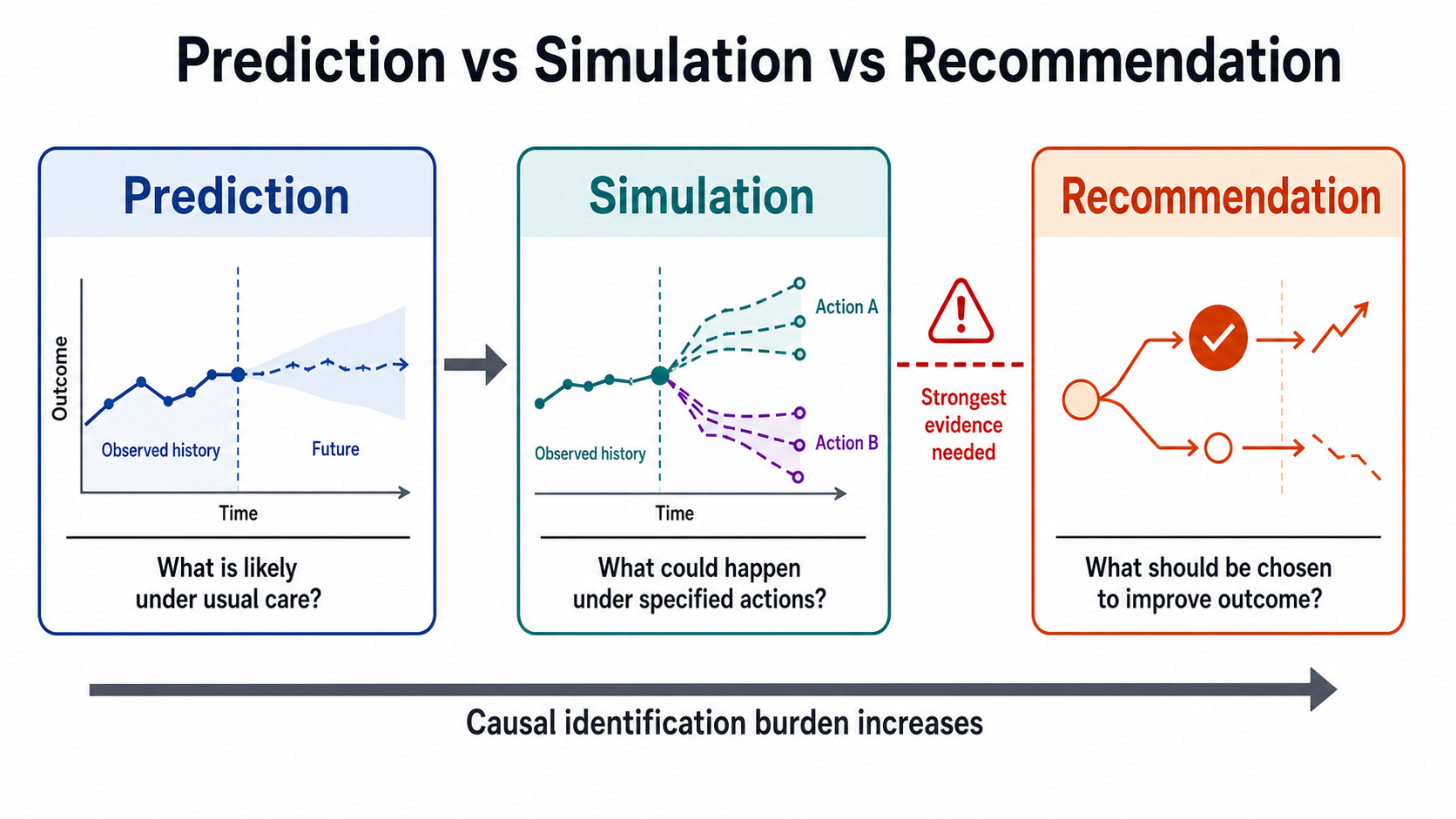
Figure 3. Prediction, simulation, and recommendation impose progressively stronger evidentiary demands. The move from plausible trajectories to treatment choice is where causal identification becomes decisive.
- Prediction: what is likely to happen if care continues as usual?
- Simulation: what trajectories are plausible under a specified intervention?
- Causal recommendation: which intervention should be chosen to improve outcome?
Prediction can be useful without being causal. Simulation can be useful if assumptions are explicit. Recommendation requires the strongest evidence and the most humility. A model that predicts creatinine well does not automatically know the effect of diuretics. A model that forecasts shock progression does not automatically know the right fluid strategy. A model that retrieves similar patients does not automatically become a digital twin.
This is the conceptual hygiene clinical AI needs before world models enter decision support.
9. Evaluation has to become physiological, not just statistical
Clinical AI is still too comfortable with retrospective discrimination. AUROC is not useless. It is simply too small a measurement for the systems now being proposed.
A physiologic world model should be evaluated across multiple layers.
First, it needs ordinary statistical performance: discrimination, calibration, Brier score, time-dependent accuracy, and robustness across sites and periods. Second, it needs operational performance: lead time, alert volume, positive predictive value at fixed workload, decision-curve net benefit, and impact on clinician attention. Third, it needs state validity: whether its latent representations correspond to clinically meaningful trajectories, organ-system behaviour, treatment response, or expert-assessed state. Fourth, it needs uncertainty validity: whether it becomes less confident when data are sparse, shifted, contradictory, or outside support. Fifth, it needs prospective evidence: silent trials before visible deployment, followed by impact studies when the tool changes care.
Table 2. Evaluation layers for physiologic world models.
| Layer | Question | Example measures | Failure mode |
|---|---|---|---|
| Statistical performance | Does the model predict observed outcomes reliably? | Discrimination, calibration, Brier score, time-dependent accuracy, external validation. | Strong retrospective AUROC hides poor calibration, temporal drift, or site brittleness. |
| Operational performance | Does the model help at a usable workload? | Lead time, alert volume, PPV at fixed review capacity, decision-curve net benefit. | Accurate scores arrive too late or create an intolerable false-alarm burden. |
| State validity | Does the latent state correspond to clinically meaningful physiology? | Expert review, organ-system trajectories, treatment-response strata, phenotype stability. | The embedding predicts labels but cannot support coherent state interpretation. |
| Uncertainty validity | Does uncertainty rise when evidence is weak? | Coverage, conformal sets, support checks, shift detection, disagreement across modalities. | The model is overconfident in sparse, shifted, contradictory, or out-of-support cases. |
| Prospective evidence | Does the full workflow improve care when deployed? | Silent trial performance, clinician response, time-to-action, outcome impact, subgroup safety. | The model works offline but fails once alerts, staffing, and feedback loops change behavior. |
The validation question should not be “does the model predict sepsis?” It should be more precise:
- Does it estimate shock state before irreversible organ injury?
- Does it remain calibrated in another hospital?
- Does it reduce false alarms at a fixed lead time?
- Does it identify when lactate absence is informative versus meaningless?
- Does it handle patients with missing imaging, sparse labs, unusual devices, or rare comorbidities?
- Does it preserve net benefit across subgroups?
- Does it expose uncertainty in a way clinicians can actually use?
- Does it improve care when embedded into workflow?
A model that cannot survive these questions should not be sold as understanding physiology.
10. A practical builder’s blueprint
A serious program should not begin with “let us build a general hospital world model.” That is too broad, too underidentified, and too easy to turn into an expensive representation-learning project with unclear clinical value.
Start with a disease process and a decision.
Good initial domains have dense signals, repeated decisions, and clinically meaningful dynamics: septic shock resuscitation, respiratory failure escalation, AKI progression and renal recovery, cardiorenal congestion, heart-failure monitoring, anticoagulation decisions in pulmonary embolism, neoadjuvant oncology response, insulin-glucose control, or post-operative decompensation.
Then define the state abstraction before the architecture. For AKI, the model should not merely predict KDIGO stage. It should represent injury, filtration, lag, volume state, congestion, nephrotoxic exposure, obstruction probability, and recovery velocity. For respiratory failure, it should separate oxygenation, ventilation, work of breathing, imaging burden, hemodynamic tolerance, and device response. For oncology, it should separate tumour burden, treatment exposure, toxicity, immune response, radiologic measurement uncertainty, and clonal escape.
Only after that should architecture enter.
The data model must preserve time. Hard binning destroys the semantics of clinical care. The observation model must handle irregularity and informative missingness. The action channel must be explicit. The latent state should be factorized enough to support organ-specific reasoning while retaining whole-patient coupling. The uncertainty layer should be built from the beginning, not attached as a figure near the end of the paper. The evaluation plan should be designed with clinical deployment in mind: actionable lead time, alert burden, net benefit, calibration, subgroup analysis, external validation, and silent prospective testing.
The technical stack may include transformers, state-space models, neural controlled differential equations, Gaussian processes, multimodal contrastive learning, mechanistic priors, causal sequence models, and conformal prediction. But the architecture is secondary to the clinical factorization.
The correct order is:
disease process -> decision -> latent state -> observations -> actions -> uncertainty -> validation -> workflow
Not:
foundation model -> embedding -> benchmark -> claim of digital twin
11. Where Biohub, DeepMind, World Labs, and clinical AI meet
The important pattern across frontier work is not that every field is solving the same problem. It is that several fields are converging on the same abstraction.
World Labs is trying to lift pixels into persistent, editable, spatially coherent 3D worlds. DeepMind’s Genie is trying to generate interactive environments where actions alter the future path. LeCun’s JEPA and AMI vision emphasize abstract predictive representations rather than exhaustive pixel-level generation. AlphaFold and Biohub’s ESM ecosystem push biological modeling from surface sequence to structure, interaction, and design.
Clinical AI should take the lesson but not copy the surface form.
The patient is not a room. The ICU is not a game. Biology is not text. But the underlying demand is similar: learn the hidden structure that makes future observations predictable and actions consequential.
For medicine, that hidden structure is physiology.
This is where the phrase “physiologic world model” earns its specificity. The model is not trying to generate an explorable 3D hospital. It is not trying to autocomplete the EHR. It is not trying to replace mechanistic science with a giant black box. It is trying to represent the patient as a partially observed, multi-organ, intervention-responsive system.
The clinical version will need to be more modest than general AI demos and more rigorous than many retrospective prediction papers. It will need hybrid structure: learned representations where data are rich, mechanistic constraints where biology is known, causal discipline where interventions are claimed, and conservative uncertainty where identification is weak.
12. What everyone will overclaim
Several overclaims are predictable.
The first is that a large EHR foundation model is already a world model. It may be a useful encoder. It may produce strong embeddings. It may transfer across tasks. But unless it represents state, observations, actions, uncertainty, and dynamics, it is not yet a physiologic world model.
The second is that a digital twin exists because a dashboard updates when new labs arrive. Updating a risk score is not twinning. A twin implies a patient-specific model whose internal state and dynamics are meaningful enough to support individualized forecasting or simulation.
The third is that multimodal fusion automatically improves medicine. It does not. More modalities can mean more missingness, more indication bias, more alignment error, more hidden shortcuts, and more opportunities for failure under shift. Fusion helps only when the modalities are complementary, time-aligned, uncertainty-aware, and robust to absence.
The fourth is that offline reinforcement learning can discover treatment policies from historical ICU data without a serious causal account. It cannot. A policy learner without a defensible state representation and action support is a high-dimensional way to rediscover confounding by indication.
The fifth is that prospective deployment validates the model alone. It does not. It validates a sociotechnical system: model, alert, interface, clinician response, staffing, escalation pathway, institutional culture, and feedback loop. A useful clinical AI system can improve outcomes without the model itself “understanding” physiology. Conversely, a good model can fail if embedded badly.
These distinctions are not academic. They are the difference between useful clinical intelligence and polished automation.
13. The next five years
The credible research agenda is not an autonomous physician model. It is a sequence of scoped, validated patient-state models.
The first generation will likely succeed in narrow, data-rich settings: ICU circulatory failure, AKI recovery, respiratory failure escalation, heart-failure congestion, ECG-to-echo latent structural disease, insulin-glucose control, and selected oncology response models. These domains have repeated measurements, meaningful interventions, and clinically important trajectories.
The second generation will connect modalities more coherently. Instead of treating imaging, notes, labs, ECG, and waveforms as a pile of features, models will learn which part of state each modality observes, when that observation is reliable, and when missingness itself is informative.
The third generation will become more action-aware. It will not simply ask what usually happened after a patient like this received vasopressors or dialysis. It will ask whether the action is within support, whether the counterfactual is identifiable, and how uncertainty should constrain any recommendation.
The fourth generation will combine learned and mechanistic models. Purely neural systems will struggle when asked to extrapolate outside the data. Purely mechanistic systems will struggle to capture the messy heterogeneity of real patients. The likely path is hybrid: mechanistic priors for physiology, learned residuals for complexity, and explicit uncertainty for everything not identified.
The fifth generation will be judged less by benchmark wins and more by clinical utility. The question will be whether the model improves decisions at the bedside, reduces avoidable harm, preserves clinician accountability, and remains safe under drift.
Conclusion: from scoring risk to representing consequence
Clinical AI has spent years learning to score the chart. That work mattered, but it is not the end state.
The more important transition is from label prediction to patient-state modeling. A physiologic world model should represent hidden state, partial observation, multimodal evidence, intervention, uncertainty, and consequence. It should distinguish prediction from simulation and simulation from recommendation. It should be validated prospectively, stress-tested under shift, and embedded in workflows where clinicians remain accountable.
The field now has enough ingredients to begin: temporal EHR models, high-resolution ICU forecasting, multimodal foundation models, digital-twin methods, causal inference, uncertainty quantification, and stronger evaluation standards. What it does not yet have is a complete, general-purpose, clinically deployed physiologic world model.
That absence should not discourage the work. It should discipline it.
The future of clinical AI is not a model that merely says, “this patient is high risk.” It is a model that helps answer: what state is this patient in, what is changing, what would make the future different, and how uncertain are we?
That is the difference between predicting the chart and modeling the patient.
Selected references and further reading
- David Ha and Jürgen Schmidhuber, World Models, 2018.
- Yann LeCun, A Path Towards Autonomous Machine Intelligence, 2022.
- Meta AI, V-JEPA: The next step toward advanced machine intelligence, 2024.
- AMI Labs, Real World. Real Intelligence., 2026.
- World Labs, A Functional Taxonomy of World Models, 2026.
- World Labs, Marble: A Multimodal World Model, 2025.
- Google DeepMind, Genie 3: A new frontier for world models, 2025.
- Google / Google DeepMind, Project Genie, 2026.
- Google DeepMind and Isomorphic Labs, AlphaFold 3 predicts the structure and interactions of all of life’s molecules, 2024.
- Biohub, Biohub releases a world model of protein biology, 2026.